So you are trying to identify the price or cost from a table containing values for specific date ranges. Luckily you are considering using DAX to do this.
An example of this might be interest rates, stock prices or inventory cost, where values change periodically. If you have many different sku's (stock-keeping units) where prices change frequently, across many different stores or locations, you can generate a large lookup table fairly quickly - airline prices are a prime example of this.
In today's example we will consider the purchase (or sale) of a select group of items (Sales table), for which we want to look up historic pricing data that is specific to each of 442 products, sold in 9 countries by 16 suppliers, in 5 currencies.
We have a price for each sku/country/supplier/currency combination, along with a date range for which each price is valid. If the price is still valid however, the "To Date" field is left blank:
Price values by date range

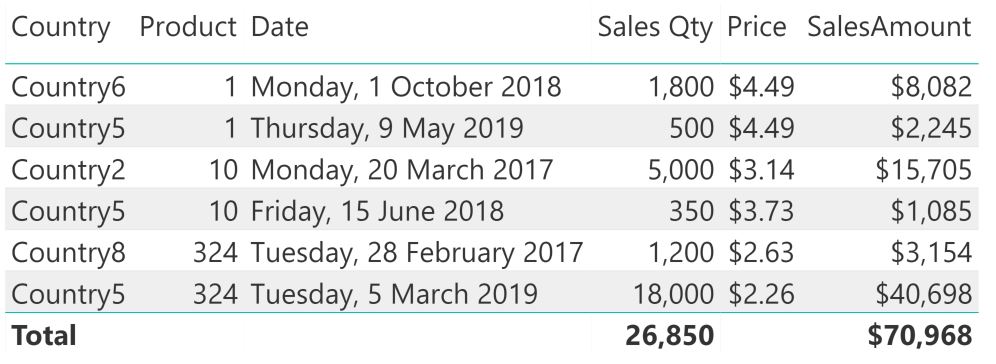
The price for each item has changed over the course of time, and we want to know, out of this lookup table containing 8,461 rows of prices, what is the total amount that our quantity of items has cost us.
While the analysis is simple enough to do in vanilla Excel with limited data, it can become very burdensome when you throw in a few more price specifics, like we have done here.
Sales table
Let's consider the Sales table for a moment:

For each product, this table shows the date on which it was bought, along with the quantity, the supplier and the country for which it is destined.
The values for Country, Product and Date all come from dimension, or lookup tables, where the data model connects data tables to lookup tables using relationships:

Something interesting happened when I connected the sales date field to the date field in the calendar. Note how it created a 1-to-1 relationship instead of a 1-to-many relationship by default. It's because in this example, there happen to be no duplicate date values in either the Sales table, or the Calendar table. In a real world scenario though, that would be the exception rather than the norm. So, we would need to modify the relationship to the Calendar table to be 1-to-many:
Power BI Data model

So how do we now look up the price we paid for each of those lines, from the Price table?
We know that the price will correspond to the date range where the transaction date falls within. Put another way, the "From Date" of the price will be earlier than the transaction date, and the "To Date" will be greater than the transaction date.
What does that mean for our constructing our price formula? For each line in our sales table, we wish to filter the price table, keeping only the rows where the sales transaction date is greater than or equal to the "From Date" of the price, but also less than the "To Date" of the price. But remember the blank "To Date" values where the prices are still valid? We can add that as an alternative to the price being less than the "To Date", where we don't have an end date value.
Luckily this is easy to write in DAX:
Price =CALCULATE (
MAX ( Prices[Amount] ),
FILTER (
Prices,
Prices[From Date] <= MAX ( Sales1[Date] )
&& (
Prices[To Date] >= MAX ( Sales1[Date] )
|| Prices[To Date] = BLANK ()
)
)
)
Let's add our Price measure to the matrix visual:
Sales table with Price DAX measure
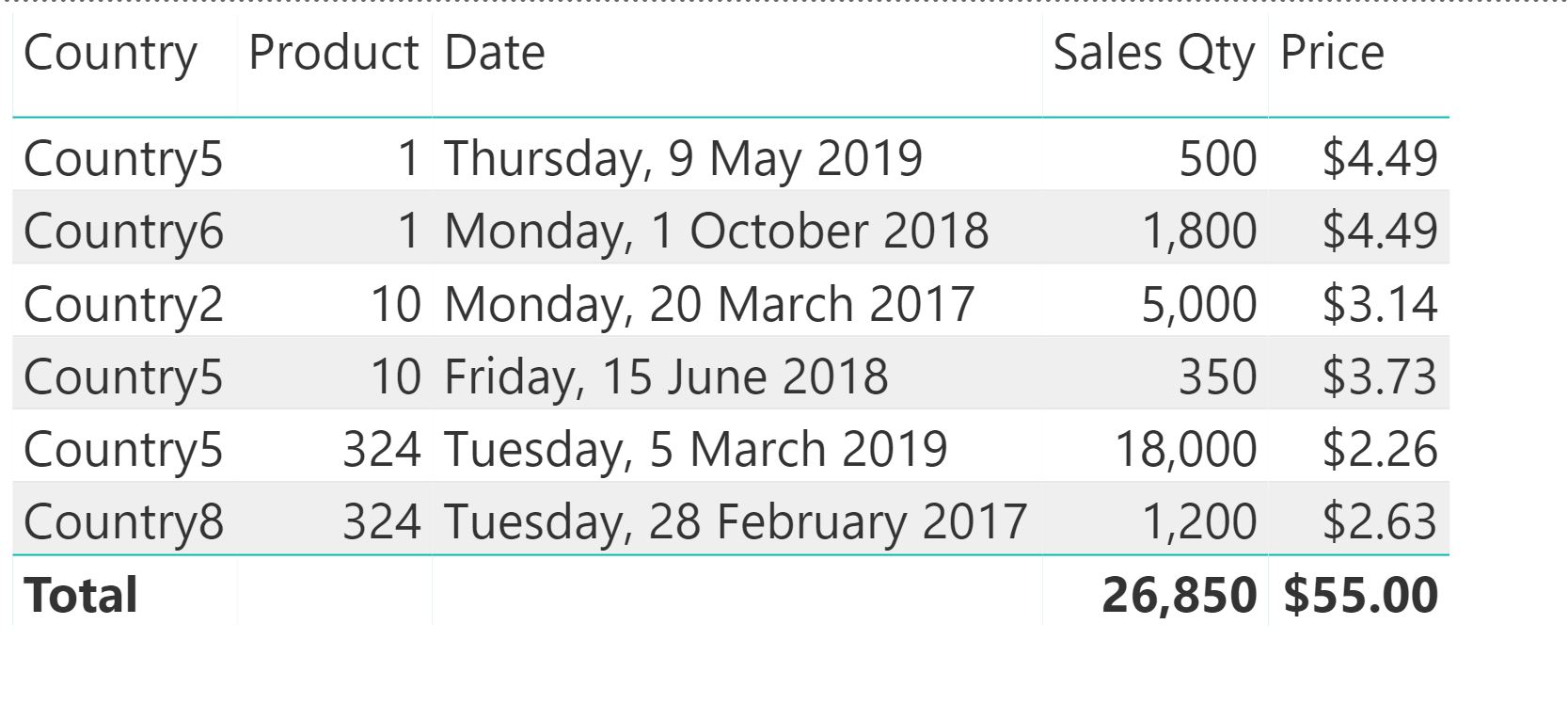
Looking at the price values for each row, we can verify that they do in fact correspond to the appropriate ranges, for each of the products and countries (you have to use lookup tables for those because you're looking at information from two data tables on the same matrix visual or pivot table). The Total row is derived with Filter Context. Thinking about how the Price measure is constructed, what would be the Maximum value (aggregator used) of the price for all products with a blank end date? Looking at the data view of our price table, with prices in descending order we can see it's 55.

Now that doesn't make sense in the context of what we are trying to convey for pricing, so we need to exclude that value from the pivot table. We can do that using the IF(HASONEVALUE()) pattern to only calculate a price for lines that have a sales date:
Price =IF (
HASONEVALUE ( Sales1[Date] ),
CALCULATE (
MAX ( Prices[Amount] ),
FILTER (
Prices,
Prices[From Date] <= MAX ( Sales1[Date] )
&& (
Prices[To Date] >= MAX ( Sales1[Date] )
|| Prices[To Date] = BLANK ()
)
)
)
)
The only part that's missing now is the Sales Amount measure, where we multiply the sales qty with the appropriate price. This can be done using the SUMX function to iterate over the sales table and calculate the appropriate total:
SalesAmount =SUMX ( Sales1, Sales1[Qty] * [Price] )
Sales table with Price and SalesAmount DAX measures